Feature Engineering + IMPALA for Google Research Football
Introduction
Google Research released their Football Environment in 2019 for research in Deep Reinforcement Learning (RL). The environment provides a realistic 3D simulation of the game of football in which the agents can control either a single player or all the players in a team. The sport of football is especially tough for RL as it requires a characteristic harmony between short-term control, learned ideas, like passing, and high-level technique. Plus this environment, can also be used for other RL research topics like impact of stochasticity, self-play, multi-agent setups and model-based reinforcement learning, while also requiring smart decisions, tactics, and strategies at multiple levels of abstraction.
|
|
|
|
|
|
Environment Details
Observation Space
A State in this environment consists of various kind of information like ball position and possession, coordinates of all players, the active player, tiredness levels of players, yellow cards, score and the current pixel frame e.t.c. There are 3 ways in which an observation for this state can be represented:
- Pixels: a 1280x720 RGB image representing the rendered image.
- Super Mini Map (SMM): Consists of four 72x96 matrices which provide information about the home team, away team, ball and the active player.
- Floats: a 115 dimensional vector which provides information like player coordinates, ball possession and direction, active player, or game mode.
Action Space
There are 19 different actions that can be performed by a player. These include move actions in 8 directions, different ways of kicking the ball, dribbling, tacking e.t.c. Detailed information regarding the action space can be found here.
Rewards
There are 2 reward functions that are provided in this environment. They are as follows:
- Scoring: In this reward function, the agent’s team gets a reward of +1 if it scores a goal and a reward of -1 if it concedes a goal to the opponent team.
- Checkpoint: This reward function divides the opponent team into 10 checkpoints and awards a reward of +0.1 if an agent is in one of these regions. This reward can go upto +1. Thus, this reward incentivizes the agent’s team to move towards opponent’s goal.
Opponent AI
There is a rule-based bot provided with the environment which can be used to train our RL algorithms. The difficulty of this bot is controlled by a parameter \(\theta\) that varies from 0 to 1. Changing this parameter influences the reaction time and decision making of the opponent team. Typically, these \(\theta\) values correspond to different difficulty levels:
- Easy (\(\theta\)=0.05)
- Hard (\(\theta\)=0.95)
We did our experiments on Easy setting.
Game Modes
There are 2 modes in which we can train our RL agent:
- Single Agent: The player closest to the ball is the active player and our RL algorithm controls the actions of this player. While this happens, the other players in our team move based on a built-in heuristic.
- Multi Agent: In this setting, each player can be controlled separately. The goal here is to train a set of agents from a random policy to a cooperating team.
Our experiments our limited to Single-Agent setting for now. Our future work involves extending to a multi agent setting.
Baselines
We used 3 baselines for our experiments. They are as follows:
stable_baselines3 was used for the implementation of these algorithms. They were trained for a total of 20M timesteps. These were evaluated every 2048 timesteps and n_eval_episodes=1. On an average, it took around 4-4.5 days to train each algorithm. We used 3 different seeds for our experiments as well.
The hyperparameters used in our experiments are as follows:
| PPO | DQN | A2C |
|---|---|---|
|
|
|
Our Approach
Feature Engineering
- Environment: We decided to use the Float-115 representation. We extended this representation to include the relative position and direction among teammates and opponents, active player and the ball. We also added sticky actions (info regarding active player), goalkeeper position and direction relative to the nearest player from both the same team and the opponent team. The resultant vector was 749 dimensional vector.
- Reward: We reshaped the reward function to reduce the sparsity in rewards. For e.g, +0.1 for gaining ball possession and -0.1 for losing it. +0.2 for a successful slide and -0.2 for an unsuccessful one. +0.001 if the team holding the ball is ours otherwise -0.001. Still a lot of fine-tuning can be done in this, but we got decent results with this when compared to the baselines.
Algorithm
We used IMPALA, a distributed off-policy reinforcement algorithm as the core RL agent. We decided to use this algorithm to speed up the training process in comparison to the baselines. For our 749-dimensional observation space, we used a 8 layer MLP feature extractor. Google Research’s Seed-RL repository was utilized for implementing the IMPALA algorithm.
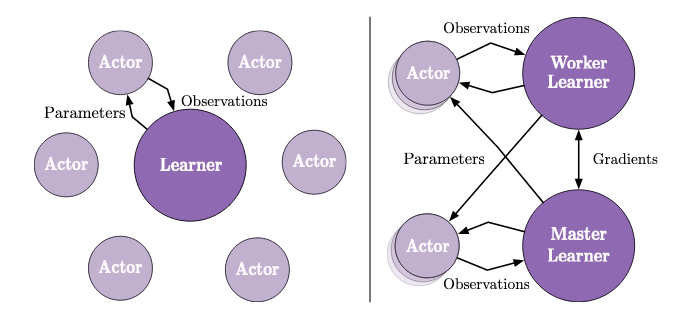
The hyperparameters used for training IMPALA are as follows:
- Total_time_steps=20M
- batch_size: 256
- num_actors=4
- eval_freq=2048
- n_eval_episodes = 1
- learning_rate=0.00038
- gamma: 0.97
- Replay_Buffer Size=30000
Results
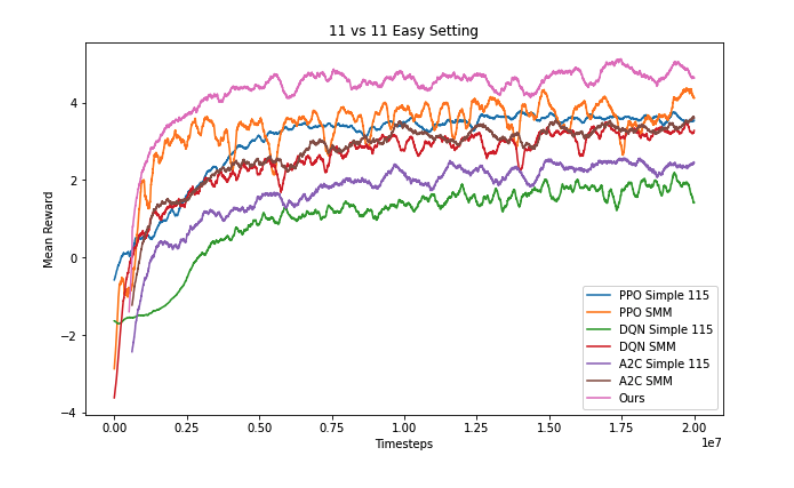
The below graph shows the results of our experiment against an 11_v_11_Easy_Bot. Our simplistic approach beat all the baselines. Result shown below is an average of 3 runs.
The below video is the simulation of our policy against an easy bot.
Few Observations
- Our agent preferred to dribble and proceed towards the opponent’s goal in order to score a goal. It didn’t learn a passing based collaborative strategy for scoring. This was probably due to the checkpoint rewards which incentivized an attacking based strategy.
- When training with a single agent, the policy being trained can only control one player at a time, while all the other players are controlled by the in-game AI (Easy teammates when opponent is Easy). It seems likely that if we train an agent with weaker teammates, it might outperform better agents if given a “smarter” team. This problem can also be fixed using multi agent training where all the players can be trained at once giving the agent full control.
Future Work
We did not get a chance to try out few of the tricks to improve the agent’s performance. They are as follows:
- Curriculum and Imitation Learning
- Self Play
- Combining RL agents with the rule based strategies, i.e learn an ensemble policy
- Adaptively changing difficulty to train our RL agents.
Hardware
All of our experiments were run on NYU Greene HPC. We used multiple nodes each consisting of 2 socket Intel Xeon Platinum 8268 24C 205W 2.9GHz Processor and 4x NVIDIA V100 GPUs.
Acknowledgement
We want to thank Dr. Lerrel Pinto for teaching this wonderful course and also the TAs for overseeing the course logistics and handling our doubts.